
你是否曾经了解过,你的电脑在访问网页时发生了什么?
域名,IP?
在文章开始之前,我们先要聊聊域名、IP这些词的含义。
注:关于IP地址与域名等相关技术本文仅进行基础概念的解释,将在后续文章中进行详细讲解。
IP是什么?
“IP” 代表互联网协议,它是一组规则,使设备可以通过互联网进行通信。每天有数十亿人访问互联网,因此需要唯一标识符来跟踪谁在做什么。互联网协议通过为每个访问互联网的设备分配 IP 编号来解决这个问题。
摘自 Cloudflare
**林恩:**想象一下,计算机的IP地址就像是你的手机电话号码。当你想要和打电话给其他人的时候,你需要知道他的手机号码才可以给他打电话。在计算机世界中,设备之间也需要通过IP地址来找到彼此,才能进行数据交换和通讯。没有IP地址,就像没有电话号码,通讯就无法实现。
例如,用户在 web 浏览器中输入某个域名时,如 google.com,就会向谷歌的 web 服务器发起请求,要求提供内容(谷歌的主页)。谷歌收到请求后,需要知道将网站内容发送到何处。因此,该请求将包含询问者的 IP 地址。通过使用提供的 IP 地址,谷歌可将回应发送回用户的设备,然后在用户的 web 浏览器中显示该内容。
摘自 Cloudflare[^3]
**林恩:**既然将IP地址比作电话号,服务器的通讯比作打电话,那么当你通过互联网访问网络的时候,你也拥有一个自己的IP地址。
IPv4 和 IPv6 的区别是什么?
IPv4 和 IPv6 是互联网协议的不同版本。IPv4 于 1983 年实施,至今仍在使用。IPv4 地址的格式是四组由点分隔的数字,例如:‘74.125.224.72’。这是一种 32 位格式,这意味着它允许 232即大约 43 亿个唯一 IP 地址,但事实证明,这对于现在互联网上的设备数量来说是不够的。对更多 IP 地址的需求导致了 IPv6 的实施。*IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:‘2607:f860:4005:804::200e’。这种 128 位格式可以支持 2^128 个唯一地址。(计算结果是一个39位数字!)
摘自 Cloudflare[^3]
IPv6 为 IPv4 提供了一些其他更新,包括安全性和隐私改进。尽管存在差异,但 IPv4 和 IPv6 已在 web 上同时使用了大约十年。这两个版本可以同步运行,但必须采取特殊措施来实现 IPv4 和 IPv6 设备之间的通信。必须做出这种妥协,因为大部分 web 仍在 IPv4 地址上运行。
摘自 Cloudflare[^3]
** IPv5怎么了? IPv5是一个从未实施的实验性流数据协议。它使用与 IPv4 相同的 32 位格式,因此不能恰当解决唯一 IP 地址不足的问题。因此,IPv6 成为 IPv4 的继任者。*
摘自 Cloudflare[^3]
**林恩:**实际上,IPV4地址早就用尽了,所以现在正在推行IPV6地址作为IPV4的替代品。
**林恩:**你有没有想过,为什么IPV4地址用尽后,你仍然可以访问互联网;既然IP地址是电话号,为什么与朋友联机的时候无法通过对方的IP地址直接"打电话"给他进行联机游玩?敬请期待下篇文章。
域名是什么?
域名是一个文本字符串,映射到一个数字 IP 地址,可用于从客户端软件访问网站。用简单的语言来说,域名是用户在浏览器窗口中键入以访问特定网站的文本。例如,Google 的域名是“google.com”。
网站的实际地址是一个复杂的数字 IP 地址(例如 103.21.244.0),但由于 DNS 的存在,用户可以输入人类友好的域名并将其路由到他们要查找的网站。此过程称为 DNS 查找。
摘自 Cloudflare[^2]
林恩:如果把IP地址比作电话号,那么域名就可以比作这个电话号存储在你通讯录中的姓名。
访问网页,从输入网址开始
什么是URL?
统一资源定位符(英语:Uniform Resource Locator,缩写:URL,或称统一资源定位器、定位地址、URL地址)俗称网页地址,简称网址,是因特网)上标准的资源的地址(Address),如同在网络上的门牌。它最初是由蒂姆·伯纳斯-李发明用来作为万维网的地址,现在它已经被万维网联盟编制为因特网标准RFC 1738)。
摘自 维基百科[^1]
网址?URL?傻傻分不清楚
**ChatGPT:**实际上,无论是"网址"还是"URL",它们都指的是相同的概念,即用于定位互联网上资源的字符串。在日常使用中,人们更常用"网址"这个词,而在技术文档或讨论中,可能会更多地使用"URL"这个术语。无论使用哪个术语,它们所描述的概念都是一样的,都是用于在互联网上定位资源的字符串标识。
**读者A:**说了这么多,那究竟网址是什么呢?为什么访问网页的时候需要Ta呢?
**林恩:简单说,在日常生活中,我们可以直接理解为,网址就是URL,在我们访问通过浏览器访问网站的时候,就是http://或https://**开头的那一串字符。
URL长什么样子?
统一资源定位符的标准格式如下:
[协议类型]://服务器地址:端口号/资源层级UNIX文件路径文件名?查询#片段ID统一资源定位符的完整格式如下:
[协议类型]://访问资源需要的凭证信息@服务器地址:端口号/资源层级UNIX文件路径文件名?查询#片段ID其中[访问凭证信息]、[端口号]、[查询]、[片段ID]都属于选填项。
摘自 维基百科[^1]
**林恩:**尽管URL有多种不同的书写方式,但它们都有一个共同的特点,那就是URL开头的文本,如“http:”、“ftp:”、“file:”,这部分文本表示了浏览器应该使用的访问方法。例如,在访问Web服务器时应使用HTTP协议,在访问FTP服务器时则应使用FTP协议。因此,我们可以将这部分视为访问时所采用的协议类型。虽然URL的后续部分可能会有不同的书写方式,但开头部分的内容决定了其后续部分的写法,因此不会造成混淆。
浏览器解析URL
首先,浏览器要对URL进行解析,然后才能向WEB服务器发送信息。
根据 HTTP 的规格,URL 包含下面的这几种元素。
- 协议
- 层级URL标记符号(为“//”,固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器(通常[域名,有时为IP地址)
- 端口号(以数字方式表示,若为默认值可省略)
- 路径(以“/”字符区别路径中的每一个目录名称)
- 查询(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与资料,通常以UTF-8的URL编码,避开字符冲突的问题)
- 片段(以“#”字符为起点)
摘自 维基百科[^1]
当对 URL 进行解析时,首先要按照上面的元素进行拆分。
1 | https://www.afdian.net/a/lynnguo666 |
如你所见,这是一个简单的爱发电赞助页面链接的分析。
当浏览器拆分后,浏览器就知道要请求的目标在哪里了,接下来,浏览器将会使用HTTP协议来访问WEB服务器。
扩展:更多的链接分析
2
3
4
5
6
7
8
9
10
11
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:password@example.com:123/path/data?key=value&key2=value2#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └─────────┬─────────┘ └──┬──┘
scheme user information host port query fragment
urn:example:mammal:monotreme:echidna
└┬┘ └──────────────┬───────────────┘
scheme path摘自 维基百科[^1]
HTTP协议的请求

HTTP 协议定义了客户端和服务器之间交互的消息内容和步骤,其基本思路非常简单。首先,客户端会向服务器发送请求消息。请求消息中包含的内容是“对什么”和“进行怎样的操作”两个部分。其中相当于“对什么”的部分称为 URI 。一般来说,URI 的内容是一个存放网页数据的文件名或者是一个 CGI 程序的文件名,例如“/dir1/file1.html”“/dir1/program1.cgi”等。不过,URI 不仅限于此,也可以直接使用“http:”开头的 URL来作为 URI。换句话说就是,这里可以写各种访问目标,而这些访问目标统称为 URI。
——《网络是怎样连接的》[^4]
HTTP 的主要方法
| 方法 | HTTP版本 1.0 | HTTP版本 1.1 | 含义 |
|---|---|---|---|
| GET | ○ | ○ | 获取 URI 指定的信息。如果 URI 指定的是文件,则返回文件的内容;如果 URI 指定的是 CGI 程序,则返回该程序的输出数据 |
| POST | ○ | ○ | 从客户端向服务器发送数据。一般用于发送表单中填写的数据等情况下 |
| HEAD | ○ | ○ | 和 GET 基本相同。不过它只返回 HTTP 的消息头(message header),而并不返回数据的内容。用于获取文件最后更新时间等属性信息 |
| OPTIONS | ○ | 用于通知或查询通信选项 | |
| PUT | △ | ○ | 替换 URI 指定的服务器上的文件。如果 URI 指定的文件不存在,则创建该文件 |
| DELETE | △ | ○ | 删除 URI 指定的服务器上的文件 |
| TRACE | ○ | 将服务器收到的请求行和头部(header)直接返回给客户端。用于在使用代理的环境中检查改写请求的情况 | |
| CONNECT | ○ | 使用代理传输加密消息时使用的方法 |
○:在该版本的规格中定义的项目。
△:并非正式规格,而是在规格书附录(Appendix)中定义的附加功能。
上述 1.0 版本和 1.1 版本的描述分别基于 RFC1945 和 RFC2616。
林恩:实际上,HTTP协议在我们普通人的使用中,最常见的方法就是GET和POST了。
林恩:其中,当我们访问网页的时候,使用的方法就是GET。
林恩:当我们在网页执行填写表单等操作的时候,使用的方法是POST。
一般当我们访问 Web 服务器获取网页数据时,使用的就是 GET 方法。一般的访问过程大概就是这样的:首先,在请求消息中写上 GET 方法,然后在 URI 中写上存放网页数据的文件名“/dir1/file1.html”,这就表示我们需要获取 /dir1/file1.html 文件中的数据。当 Web 服务器收到消息后,会打开 /dir1/file1.html 文件并读取出里面的数据,然后将读出的数据存放到响应消息中,并返回给客户端。最后,客户端浏览器会收到这些数据并显示在屏幕上。
使用 POST 方法时,URI 会指向 Web 服务器中运行的一个应用程序的文件名,典型的例子包括“index.cgi”“index.php”等。然后,在请求消息中,除了方法和 URI 之外,还要加上传递给应用程序和脚本的数据。这里的数据也就是用户在输入框里填写的信息。当服务器收到消息后,Web 服务器会将请求消息中的数据发送给 URI 指定的应用程序。最后,Web 服务器从应用程序接收输出的结果,会将它存放到响应消息中并返回给客户端。
——《网络是怎样连接的》[^4]
HTTP 的请求信息
浏览器确定了Web服务器、需要请求的文件名后,就可以根据这些信息生成HTTP的请求信息了。
HTTP信息在格式上有严格的规定,因此浏览器会按照规定的格式来生成请求的信息。

**林恩:**关于消息头等内容,你可以阅读本文后的扩展内容来进行学习。
HTTP 的回应
当HTTP请求信息发出后,Web服务器会返回一条响应信息,里面会包含状态码以及响应短语。
状态码的第一位数字表示状态类型,第二、三位数字表示具体的情况。下表列举了第一位数字的含义。
| 状态码 | 含义 |
|---|---|
| 1xx | 告知请求的处理进度和情况 |
| 2xx | 成功 |
| 3xx | 表示需要进一步操作 |
| 4xx | 客户端错误 |
| 5xx | 服务器错误 |
**林恩:**有的时候我们访问网页的时候会看到网页显示404 Not Found,这就是状态码的显示。
**林恩:**如果网页访问成功了,那么状态码就是200。
向DNS服务器获取服务器IP
DNS是什么?
域名系统 (DNS) 是互联网的电话簿。人们通过例如 nytimes.com 或 espn.com 等域名在线访问信息。Web 浏览器通过 互联网协议 (IP) 地址进行交互。DNS 将域名转换为 IP 地址,以便浏览器能够加载互联网资源。
连接到 Internet 的每个设备都有一个唯一 IP 地址,其他计算机可使用该 IP 地址查找此设备。DNS 服务器使人们无需存储例如 192.168.1.1(IPv4 中)等 IP 地址或更复杂的较新字母数字 IP 地址,例如 2400:cb00:2048:1::c629:d7a2(IPv6 中)。
摘自 Cloudflare
DNS是如何处理浏览器发出的请求的?
**林恩:**你可以通过这张图来简单了解DNS是如何运作的,实际上DNS的运行规则比这个更加的复杂。
**林恩:**当获取到IP地址后,浏览器将会将请求的信息发送至对应的IP地址,并等待Web服务器的回应。
**林恩:**通过 DNS 获取到 IP 后,就可以把 HTTP 的传输工作交给操作系统中的协议栈。系统会根据定义好的协议栈来进行数据处理,并且发送数据到对应的服务器,同时等待返回的数据,当返回的数据获取到后,将会将数据交给浏览器进行处理,这样,浏览器就显示了我们所见到的网页。
**林恩:**本文主要的讲述内容到此就结束了,关于协议栈等后续知识点暂时不需要理解,如果你感兴趣,可以阅读本文末尾的扩展资料。
简单理解:到底发生了什么
从写信的角度来理解
**林恩:**你可以尝试这样理解:
当我们输入URL后,相当于写了一封信,想要从指定的那个人(域名)手中获得一份资料(网页内容),而这份资料的名称跟随在域名的后面**(URL中的路径),浏览器相当于邮局的前台**,当收到你的信后按照HTTP的规范填写了信封上面的内容**(HTTP请求报文)**。
这封信在所有内容按照格式填写后,交到了邮局手中,邮局的后台(操作系统中的Socket库)按照你给出的地址(域名),从一本厚厚的通讯录(DNS服务器)中找到了你想要将信送达的那个人(域名)的电话号码(IP地址),然后邮局前台就委托后台(Socket库)让后台打电话(建立连接)给那个人(域名),告知了那个人信(HTTP请求信息)中的内容。对方收到了信中的内容后,就开始按照你给出的信封地址(URL中的路径)寻找对应的资料(网页),无论是否找到,对方都要给你一个答复(HTTP状态码)。
如果对方找到了这个文件,那么他就会要求邮局建立一个路线(创建套接字、建立连接),将资料(网页)发送给你的邮局(Socket库),并且关闭了这条路线(断开连接、删除套接字),邮局收到了资料后将文件转交给前台(浏览器),前台处理文件后就将资料展示给我们以供查看了。
当然,这只是一个简单的比喻,实际上获取网页的规则要复杂许多,因为现代的网页不再是单独的文字,而是包含许多媒体、样式,所以浏览器需要按照规则来请求这些数据。
总结:这段时间浏览器都做了什么
- URL输入与解析:在浏览器的地址栏中输入URL(统一资源定位符),这是网站的网址。浏览器会解析这个URL,提取出其中的域名部分。
- DNS解析:浏览器向DNS服务器查询域名对应的IP地址。DNS服务器将域名转换成IP地址,使浏览器知道要连接哪个服务器。
- 建立连接:浏览器使用IP地址与目标服务器建立连接,通常通过TCP/IP协议来确保数据传输的可靠性。
- 发起HTTP请求:浏览器向服务器发送HTTP请求,请求特定的资源,如网页文件、图片、视频等。请求包含了资源的类型、方法和其他信息。
- 服务器处理请求:服务器接收到浏览器的请求后,开始处理。它会查找请求的资源,验证权限等,然后准备响应。
- HTTP响应发送:服务器生成HTTP响应,其中包含了响应状态码、响应头和响应主体。响应主体可能是请求的资源内容。
- 接收和处理响应:浏览器接收到服务器的HTTP响应后,开始解析响应。根据响应的内容类型,浏览器决定如何处理响应,例如是显示HTML内容还是下载文件。
- 页面渲染:如果响应内容是HTML,浏览器解析HTML标记,构建页面的结构。同时,浏览器会加载和解析CSS样式表,应用于页面,确保页面的外观。
- 资源加载:浏览器根据HTML解析结果,发现还有其他资源需要加载,如图片、视频、音频等。浏览器会并行加载这些资源,以提高页面加载速度。
- 页面呈现:当所有资源加载完成且解析完成后,浏览器将网页内容呈现在屏幕上,供用户浏览和与之交互。
后记
**林恩:**如果你喜欢我的文章,可以考虑在爱发电赞助我,这会激励我更有动力地写更多的文章。
爱发电:https://afdian.net/a/lynnguo666
下篇文章预告:
《简单说说:为什么IPV4用尽了我还可以登入互联网?》
扩展内容
信息传递:数据收发
知道了 IP 地址之后,就可以委托操作系统内部的协议栈向这个目标 IP 地址,也就是我们要访问的 Web 服务器发送消息了。要发送给 Web 服务器的 HTTP 消息是一种数字信息(digital data),因此也可以说是委托协议栈来发送数字信息。收发数字信息这一操作不仅限于浏览器,对于各种使用网络的应用程序来说都是共通的。因此,这一操作的过程也不仅适用于 Web,而是适用于任何网络应用程序 。
——《网络是怎样连接的》[^4]
向操作系统内部的协议栈发出委托时,需要按照指定的顺序来调用 Socket 库中的程序组件。
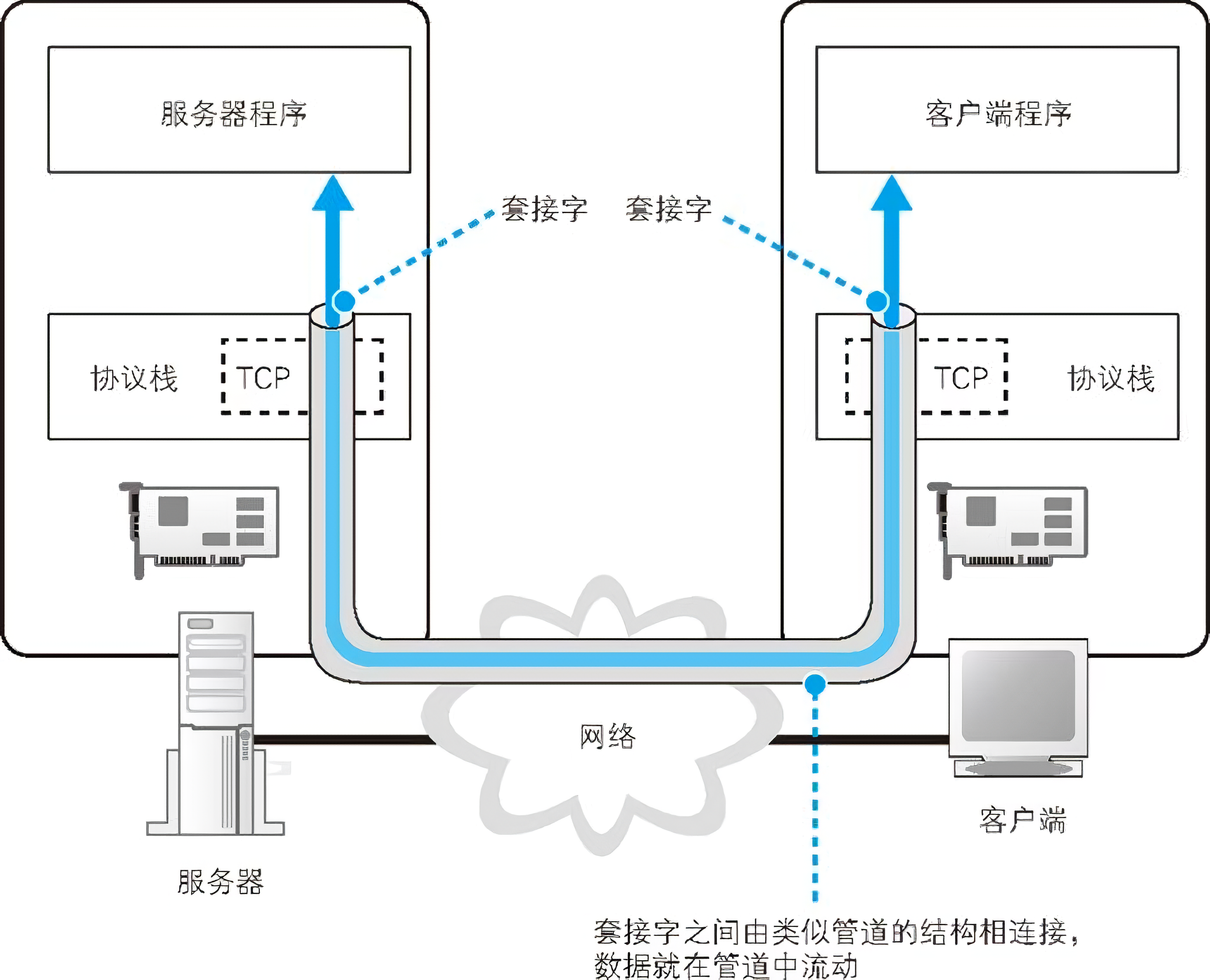
使用 Socket 库来收发数据的操作过程如图所示 。简单来说,收发数据的两台计算机之间连接了一条数据通道,数据沿着这条通道流动,最终到达目的地。我们可以把数据通道想象成一条管道,将数据从一端送入管道,数据就会到达管道的另一端然后被取出。数据可以从任何一端被送入管道,数据的流动是双向的。不过,这并不是说现实中真的有这么一条管道,只是为了帮助大家理解数据收发操作的全貌。
——《网络是怎样连接的》[^4]
林恩:如果从图上来看,这条管道好像一开始就已经存在了,实际上这条管道并不存在,需要我们在收发数据前进行建立,建立管道的关键在于管道两端的数据出入口,这些出入口称为套接字。
收发操作我们可以大致分为以下四步:
-
创建套接字(创建套接字阶段)
-
将管道连接到服务器端的套接字上(连接阶段)
-
收发数据(通信阶段)
-
断开管道并删除套接字(断开阶段)

Socket库是什么?
A network socket is a software structure within a network node of a computer network that serves as an endpoint for sending and receiving data across the network. The structure and properties of a socket are defined by an application programming interface (API) for the networking architecture. Sockets are created only during the lifetime of a process of an application running in the node.
网络套接字是计算机网络网络节点内的软件结构,用作通过网络发送和接收数据的端点。套接字的结构和属性由网络体系结构的应用程序编程接口 (API) 定义。套接字仅在节点中运行的应用程序的进程的生存期内创建。Because of the standardization of the TCP/IP protocols in the development of the Internet, the term network socket is most commonly used in the context of the Internet protocol suite, and is therefore often also referred to as Internet socket. In this context, a socket is externally identified to other hosts by its socket address, which is the triad of transport protocol, IP address, and port number.
由于TCP/IP协议在互联网发展中的标准化,术语网络套接字最常用于互联网协议套件的上下文中,因此通常也称为互联网套接字。在此上下文中,套接字通过其套接字地址(传输协议、IP 地址和端口号的三位一体)在外部标识给其他主机。The term socket is also used for the software endpoint of node-internal inter-process communication (IPC), which often uses the same API as a network socket.
术语套接字还用于节点内部进程间通信 (IPC) 的软件端点,它通常使用与网络套接字相同的 API。摘自 维基百科[^5]
**ChatGPT:**Socket 库是计算机编程中用于网络通信的一个标准库,它提供了一组函数和类,用于在计算机网络之间建立连接、发送和接收数据。通过 socket 库,开发人员可以创建各种类型的网络应用程序,包括客户端和服务器。
**ChatGPT:**在网络编程中,socket库提供了一种抽象层,使得开发人员可以通过不同的协议(如TCP、UDP等)进行数据传输,而不需要深入了解底层的网络细节。它允许在不同的计算机之间建立连接,以便它们可以交换数据或执行其他网络操作。